LM Studio本地部署语言模型构建API服务并利用python进行调用
一、环境配置
1.操作系统及硬件配置
Windows 10 专业版
CPU:Intel(R) Core(TM) i5-10400 CPU @ 2.90GHz 2.90 GHz
内存:32GB(实际占用不到16GB)
GPU:NVIDIA GeForce RTX 3060 (12G)
2.N卡驱动及CUDA安装
3.python环境
Python 3.X
requests库
二、安装LM Studio与选择语言模型
1.安装LM Studio
安装完成Windows版本
启动之后的界面
2.模型下载
Hugging Face 🤗 或者直接使用 LM Studio 的Discover功能(需要魔法)
魔搭社区的模型库(速度快,推荐)
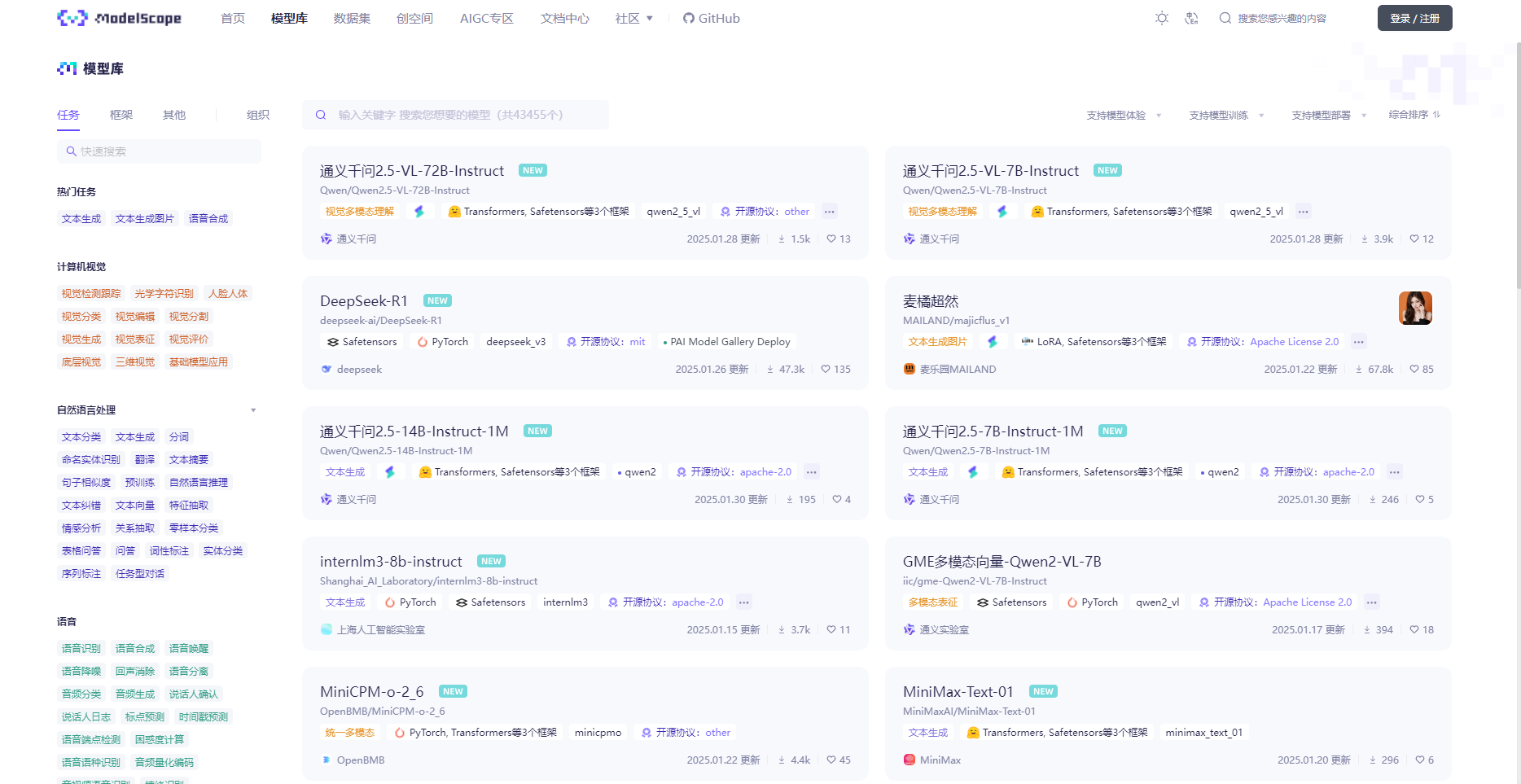
接下来就要选择一个适合自己的模型了,这里以最近很火的DeepSeek-R1为例
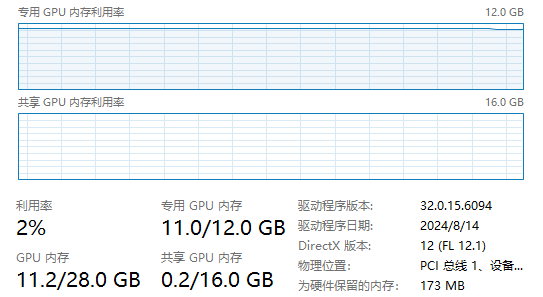
如你所见,这里有许多不同的DeepSeek模型(直接从网站上复制的),但是我们自然要选择一个最适合自己的,对于我RTX 3060 (12G)的配置来说,选择一个10G左右的模型差不多可以流畅运行(这里的内存指的是专用GPU内存)
所以权衡之后我选择了DeepSeek-R1-Distill-Qwen-14B-Q4_K_M进行安装,建议使用IDM下载,我下载的时候速度大概能到20MB/s,还是比较快的。
三、加载语言模型
这一步比较简单,但可能是除去下载模型以外耗时最久的
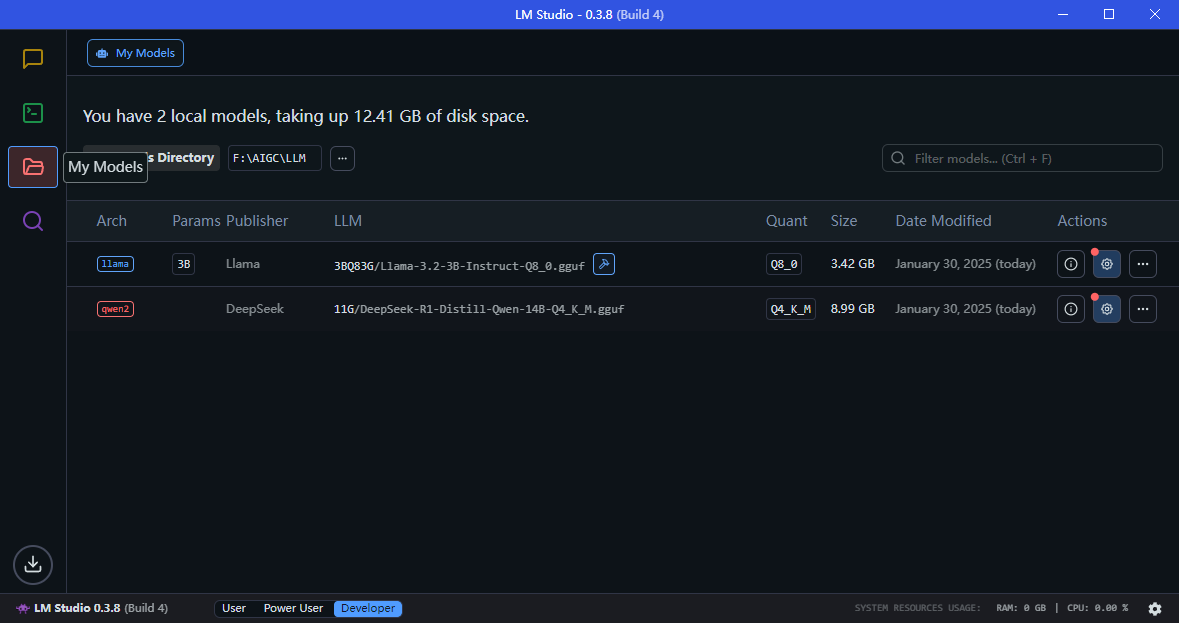
你只需要在My Models下查看你的模型目录(建议选择一个固态硬盘下的目录)
然后把模型文件放进去就行
注意:LM Studio对于模型文件的目录有要求,比如我这里的模型目录是[F:\AIGC\LLM]但实际上我的目录是这样的
F:\AIGC\LLM
├─DeepSeek
│ └─11G
└─Llama
└─3BQ83G其中,我的模型目录是在LLM的二级目录下的,只有这样设计文件夹才能被LM Studio正确读取
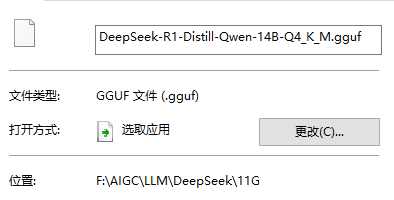
如果你已经完成以上步骤,那就应该可以看到你的模型文件了
现在回到Chat界面,你就应该可以进行模型加载了
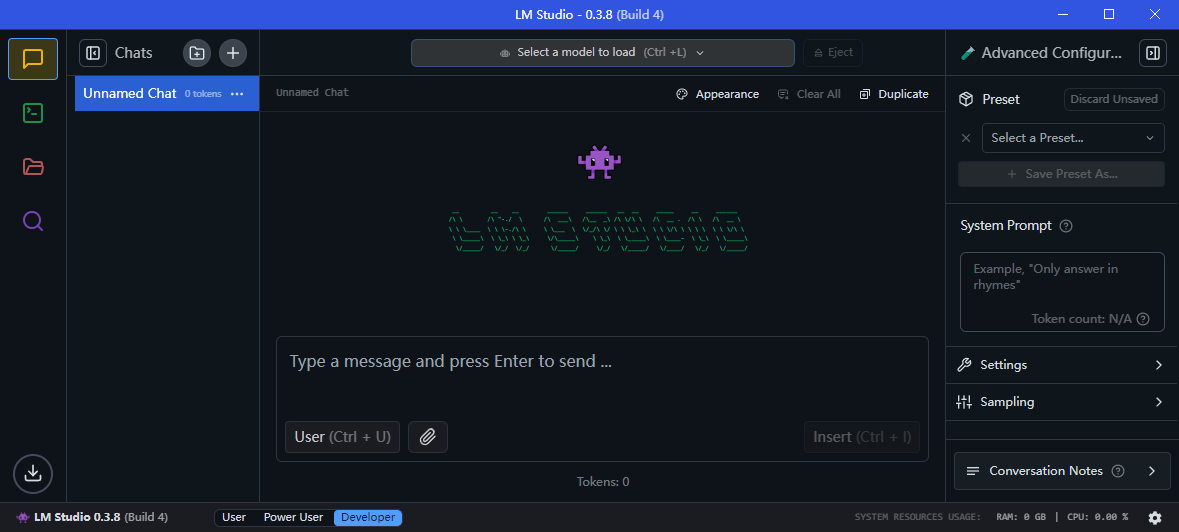
点击 Select a model to load(最上面那个按钮),然后选择你的模型文件并加载
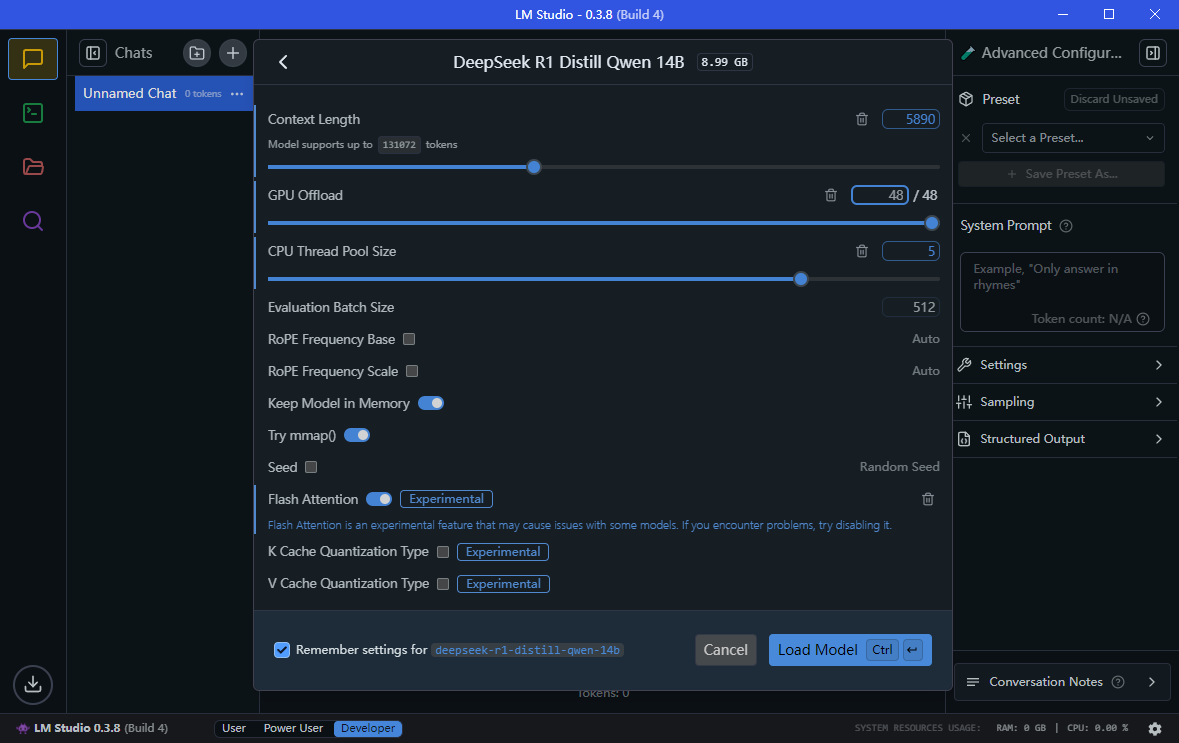
GPU如果没有运行其他程序或者渲染什么东西的话建议直接拉满,毕竟LLM都是比较耗费算力和内存的
CPU如果不是高压状态也可以给满
Flash Attention(快速注意力),这个可以让你的语言模型响应速度更快,虽然写着不稳定。不过我在使用的时候发现其实还蛮稳定的,至少到现在也没出任何问题。
 加载模型,不出意外你应该已经可以听到显卡的咆哮了,所以一定要记得不使用的时候点击这个Eject退出加载,不然会一直占用你的显存
加载模型,不出意外你应该已经可以听到显卡的咆哮了,所以一定要记得不使用的时候点击这个Eject退出加载,不然会一直占用你的显存

到这一步,我们的模型加载也完成了,我们可以初步尝试使用了
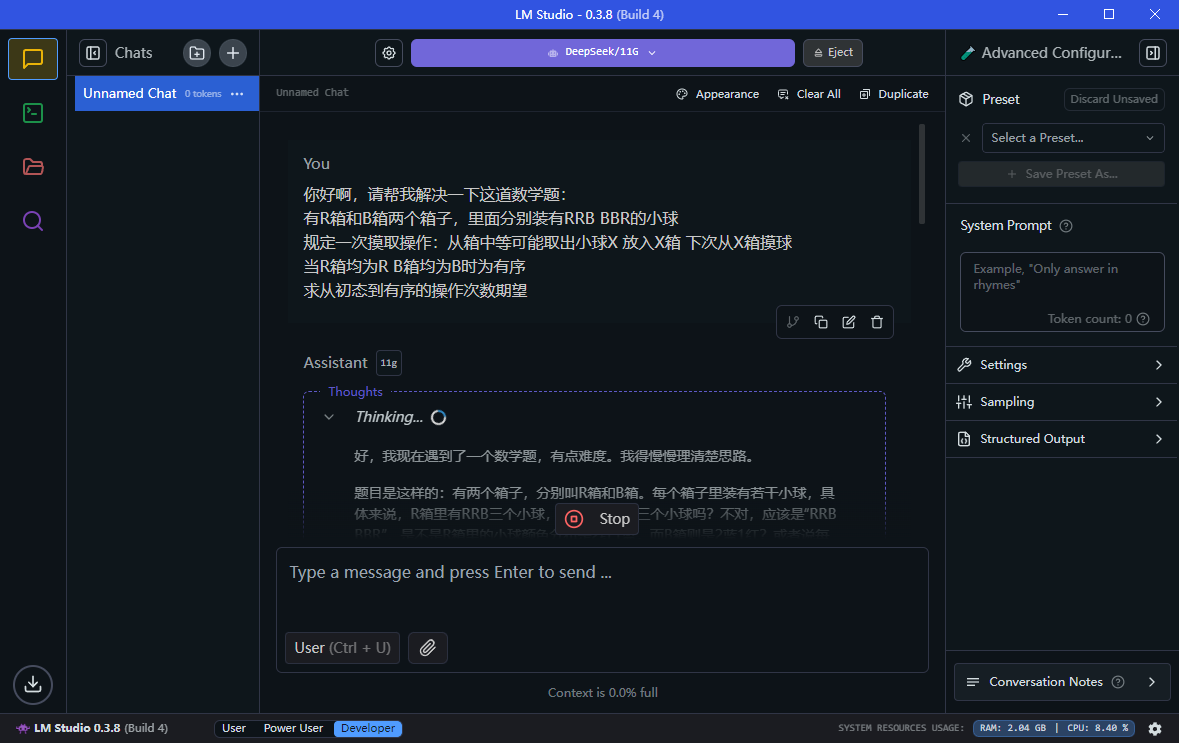
(被一道简单的马尔科夫链烧到大脑的DeepSeek.jpg)

(好吧,他已经为此讨论半天了,看来马尔科夫链还是当之无愧的AI杀手,不过可以看到本地的响应速度还是很快的)
四、启动API服务
在LM Studio内启动API服务即可,这一步动动鼠标就能完成
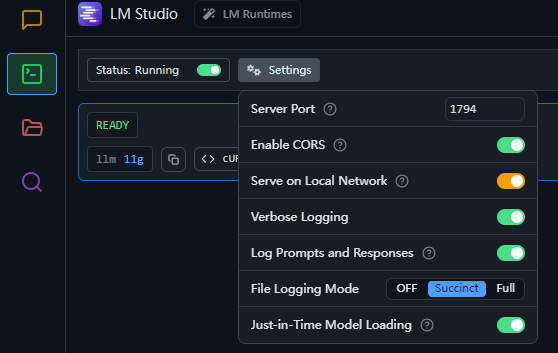
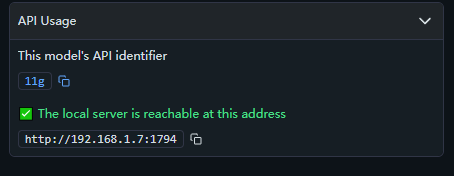
不过如果是没有用过OpenAI给的GPT的API的话,可能还是一头雾水,当然LM Studio自己也写了使用文档
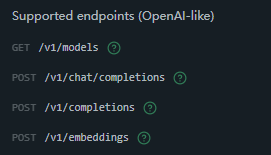
(看得出来对OpenAI的兼容性非常好,对于旧项目可以省去很多时间改代码和调试)
我们通过文档,得到了Json格式的Example using
curl http://0.0.0.0:1794/v1/chat/completions \
-H "Content-Type: application/json" \
-d '{
"model": "11g",
"messages": [
{
"role": "system",
"content": "You are a helpful jokester."
},
{
"role": "user",
"content": "Tell me a joke."
}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "joke_response",
"strict": "true",
"schema": {
"type": "object",
"properties": {
"joke": {
"type": "string"
}
},
"required": ["joke"]
}
}
},
"temperature": 0.7,
"max_tokens": 50,
"stream": false
}'
因为我们要在python中调用API,所以我们要先转成json格式
{
"model": "11g",
"messages": [
{
"role": "system",
"content": "You are a helpful jokester."
},
{
"role": "user",
"content": "Tell me a joke."
}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "joke_response",
"strict": "true",
"schema": {
"type": "object",
"properties": {
"joke": {
"type": "string"
}
},
"required": ["joke"]
}
}
},
"temperature": 0.7,
"max_tokens": 50,
"stream": false
}
注意到,这里的request data其实已经规定了我们的response_format,这个就是我们所使用的Structured Output,我们可以基于这个格式进行更丰富的开发
接下来,就是常规的request环节
import requests
headers = {
"Content-Type": "application/json"
}
data = {
"model": "11g",
"messages": [
{
"role": "system",
"content": "You are a helpful jokester."
},
{
"role": "user",
"content": "Tell me a joke."
}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "joke_response",
"strict": "true",
"schema": {
"type": "object",
"properties": {
"joke": {
"type": "string"
}
},
"required": ["joke"]
}
}
},
"temperature": 0.7,
"max_tokens": 50,
"stream": False
}
# 替换为你的本地 API 地址
response = requests.post('http://192.168.1.7:1794/v1/chat/completions', headers=headers, json=data)
if response.status_code == 200:
result = response.json()
print("Response:", result)
else:
print(f"Error: {response.status_code} - {response.text}")
运行之后,我们得到了返回的数据
{
"id": "...",
"object": "chat.completion",
"created": ...,
"model": "11g",
"choices": [
{
"index": 0,
"logprobs": None,
"finish_reason": "stop",
"message": {
"role": "assistant",
"content": "{\n \"joke\": \"Sure, here's a light-hearted joke for you: Why don't skeletons fight each other? Because they don’t have the guts!\"\n}\n"
}
}
],
}
稍作分析,我们应该从"choices"下的"content"得到我们所需的内容,也就是说我们要写一段代码,从返回的JSON结果中提取“content”,将其解析为字典,然后取出“joke”值,这里和我们的Request Data的Structured Output也对应上了
if response.status_code == 200:
result = response.json()
joke_content = result.get("choices", [{}])[0].get("message", {}).get("content", "")
try:
joke_data = eval(joke_content)
if isinstance(joke_data, dict):
joke = joke_data.get("joke", "No joke found in response.")
print("Joke:", joke)
else:
print("Unexpected content format:", joke_data)
except Exception as e:
print(f"Error parsing joke content: {e}")
else:
print(f"Error: {response.status_code} - {response.text}")(这里用try确保请求后返回的是一个正常的“Joke”)
运行
Joke: Why did the scarecrow win an award?没有问题(好)
不过如果返回的内容格式有变化,我们也要做出相应的修改,并且这次API的调用是基于官方给的样本代码上的,我们其实可以做出更多修改适用于更加丰富的场景,下面附上完整代码
import requests
headers = {
"Content-Type": "application/json"
}
data = {
"model": "11g",
"messages": [
{
"role": "system",
"content": "You are a helpful jokester."
},
{
"role": "user",
"content": "Tell me a joke."
}
],
"response_format": {
"type": "json_schema",
"json_schema": {
"name": "joke_response",
"strict": "true",
"schema": {
"type": "object",
"properties": {
"joke": {
"type": "string"
}
},
"required": ["joke"]
}
}
},
"temperature": 0.7,
"max_tokens": 50,
"stream": False
}
your_address = 'http://192.168.1.7:1794/v1/chat/completions'#改为你的API地址
response = requests.post(your_address , headers=headers, json=data)
if response.status_code == 200:
result = response.json()
joke_content = result.get("choices", [{}])[0].get("message", {}).get("content", "")
try:
joke_data = eval(joke_content)
if isinstance(joke_data, dict):
joke = joke_data.get("joke", "No joke found in response.")
print("Joke:", joke)
else:
print("Unexpected content format:", joke_data)
except Exception as e:
print(f"Error parsing joke content: {e}")
else:
print(f"Error: {response.status_code} - {response.text}")
#——新年快乐至此,我们本次尝试圆满结束,感谢阅读,新年快乐!
——By JiomLan