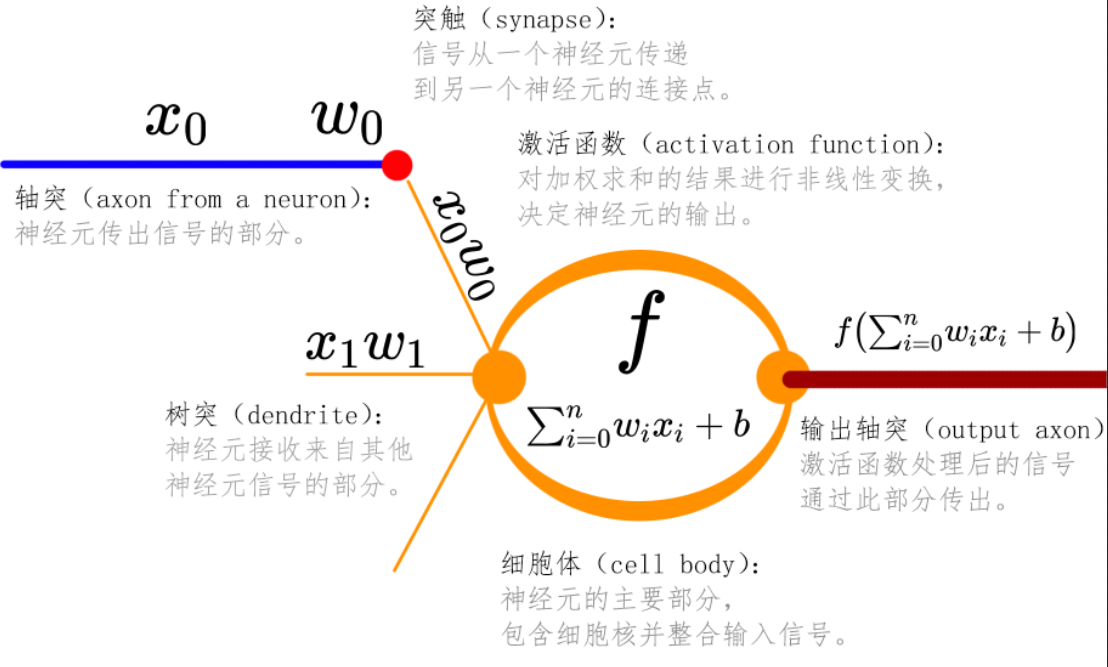
PyTorch框架深度学习笔记03-番外篇(sklearn)
在继续学习 PyTorch 之前,我们先来认识一下 sklearn 这款强大的机器学习工具包。
Sklearn介绍
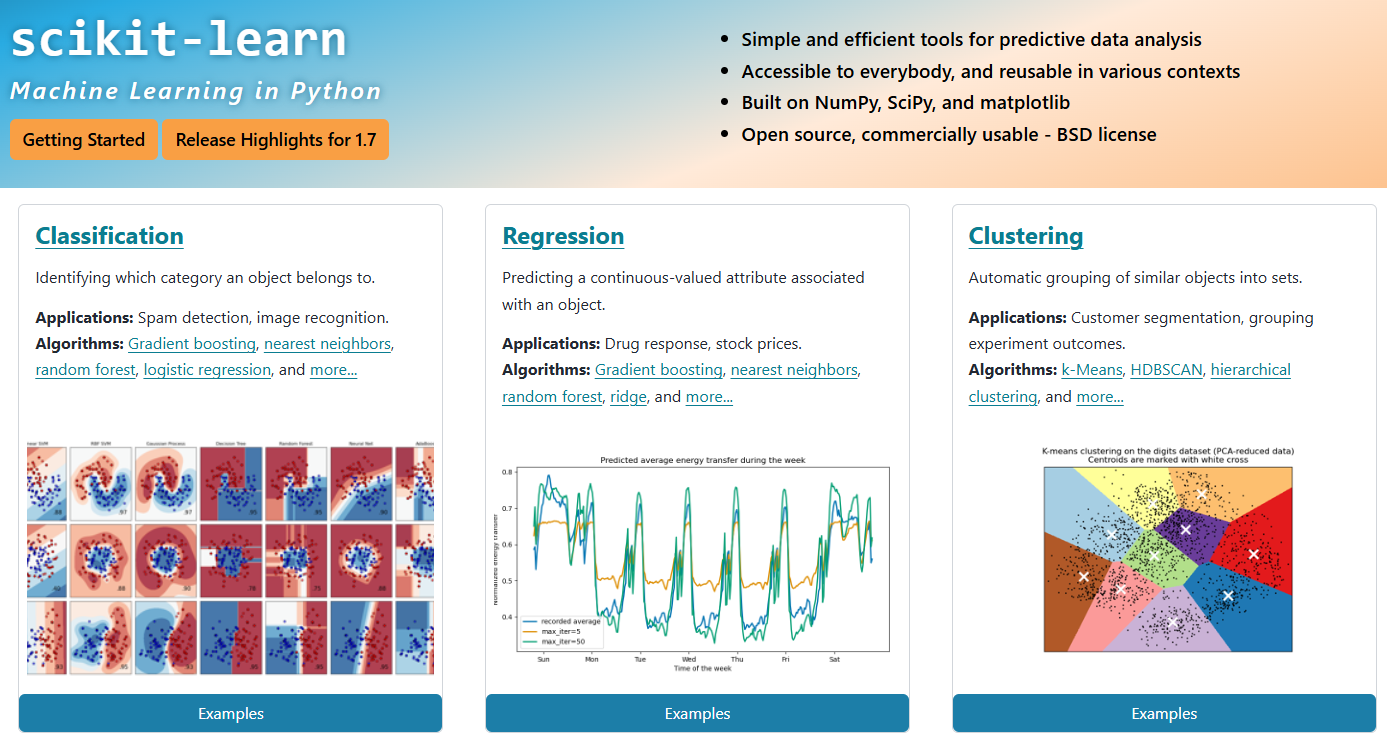
sklearn甚至可以说是当之无愧的机器学习第一工具,其自带大量数据集,并且集成各种算法,包括但不限于数据预处理、数据特征选择、分类、回归,模型评估。
比如出名的鸢尾花数据集就可以用sklearn.datasets的**load_iris( )**方法进行本地加载。只需要导入该包即可使用。
from sklearn import datasets
而且鉴于支持向量机(SVM,Support Vector Machine)的数学原理非常复杂且网上教程很多,这里就不写了。我们可以直接通过sklearn导入封装好的支持向量机。
from sklearn.svm import LinearSVC
此外,sklearn还提供了很好用的评估函数和标准化函数。
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
标准化转换器可以将特征缩放至均值为0、标准差为1的标准正态分布。
使用时可以先创建标准化转换器对象,然后进行计算,最后应用该变换。
standardScaler = StandardScaler()
standardScaler.fit(X)
X_standard = standardScaler.transform(X)
后面两行的操作分别对应了如下的数学公式
\mu =\frac{1}{n} {\textstyle \sum_{i=1}^{n}} x_{i}
\sigma = \sqrt{\frac{1}{n} {\textstyle \sum_{i=1}^{n}} \left ( x_{i}-\mu \right )^{2} }
x_{standard} = \frac{x-\mu}{\sigma}
这样的转化可以保证所有特征处于相同量级。
SVM代码实现
import numpy as np
import matplotlib.pyplot as plt
from sklearn import datasets
from sklearn.svm import SVC
from sklearn.metrics import accuracy_score
from sklearn.preprocessing import StandardScaler
接下来是数据的获取,因为我们这次写的是线性支持向量机,所以只需要取到二维的数据。
iris = datasets.load_iris()
X = iris.data
y = iris.target #获取目标标签,即每个样本对应的类别(0,1,2分别代表三种鸢尾花)
print(type(X),X)
print(type(y),y)
#这里我们写二维的SVM,所以接下来只选取两组数据
X = X[y<2,:2] #选择目标标签小于2的样本,也就是只取类别0和1(因为原始数据有三类,这里我们只取两类)
y = y[y<2]
print(type(X),X)
print(type(y),y)
我们通过输出数据类型和数据可以更好的理解训练集的类型。
比如我们可以发现这些数据类型都是 Numpy 的 ndarray。
#创建一个StandardScaler对象,用于数据的标准化处理。
#标准化是指将数据变换为均值为0,标准差为1的分布。
#SVM基于距离计算(如间隔最大化),不同特征的量纲差异会导致模型偏向数值较大的特征。标准化保证所有特征处于相同量级。
standardScaler = StandardScaler()
standardScaler.fit(X)
X_standard = standardScaler.transform(X)
#决策边界为直线,C=1E10:设置极大的惩罚参数(10^10),强制要求严格分类(硬间隔),不允许分类错误
model = SVC(kernel='linear', C=1E10)
model.fit(X_standard, y)
这一步我们进行的是数据标准化和训练,可以看到用sklearn的训练非常简单,只需一行。
#模型评估
y_pred = model.predict(X_standard)
print(type(y_pred),y_pred)
accuracy = accuracy_score(y, y_pred)
print(f"Accuracy: {accuracy:.2f}")
绘制决策边界
plt.figure(figsize=(10, 8))
plt.scatter(X[y==0,0], X[y==0,1], color='red', alpha=0.55, label='Setosa')
plt.scatter(X[y==1,0], X[y==1,1], color='blue', alpha=0.55, label='Versicolor')
#绘制决策边界
#创建网格点
xx, yy = np.meshgrid(np.linspace(3.0, 7.5, 200),np.linspace(1.5, 5.0, 200))
grid = np.c_[xx.ravel(), yy.ravel()]
#标准化网格点(使用相同的scaler)
grid_standard = standardScaler.transform(grid)
#预测网格点类别
Z = model.predict(grid_standard)
Z = Z.reshape(xx.shape)
#绘制决策边界和间隔区域
plt.contourf(xx, yy, Z, alpha=0.1, levels=[-1, 0, 1], colors=['red', 'blue'])
plt.contour(xx, yy, Z, colors='black', linewidths=1.5, alpha=0.8, levels=[0])
#添加超平面方程信息
#获取模型参数(在标准化空间)
w = model.coef_[0]
b = model.intercept_[0]
#在原始空间表示的超平面方程(需要转换)
mean = standardScaler.mean_
std = standardScaler.scale_
#转换权重到原始空间
w_original = w / std
b_original = b - np.dot(w / std, mean)
#显示超平面方程
equation = f"{w_original[0]:.2f}x + {w_original[1]:.2f}y + {b_original:.2f} = 0"
plt.text(4.0, 4.8, f"Decision Boundary:\n{equation}", bbox=dict(facecolor='white', alpha=0.8))
#设置图形属性
plt.xlim(3.0, 7.5)
plt.ylim(1.5, 5.0)
plt.xlabel('Sepal Length (cm)')
plt.ylabel('Sepal Width (cm)')
plt.title('SVM Classification of Iris Flowers')
plt.legend()
plt.grid(alpha=0.2)
plt.show()