PyTorch框架深度学习笔记02(KNN分类机)
做好所有前置准备工作后,就要正式开始学习PyTorch了,我们以简单的KNN分类机为起点,本章主要以PyTorch的代码练习为中心。
什么是KNN?
最近邻居法(K-Nearest Neighbor,又译K-近邻算法),是机器学习中最简单的算法之一。是一种可以用于分类(Classification)和回归(Regression)的非参数统计方法。
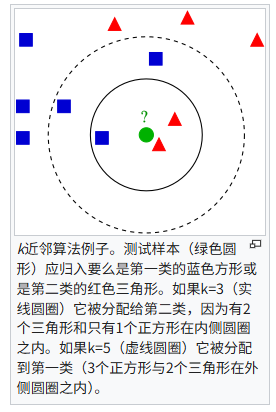
KNN算法的原理并不复杂,简单来说就是通过计算测试数据周围K个最临近的样本数据(也就是所谓的邻居)来对测试数据进行归类的算法。这样就可以依赖样本数据对测试数据进行分类,比如上图,如果K=3,也就是考虑最临近的三个数据,那么测试样本应该被归类进红色,但是如果K=5,及考虑五个数据,那么就会被归类进蓝色。由此,我们也可以发现**K值的选定**是该算法较为核心的步骤。
在KNN算法的距离计算中,我们通常运用两种距离公式:
-
欧式距离
Distances = \sqrt{\left ( x_{1}-x_{2} \right )^{2} + \left ( y_{1}-y_{2} \right )^{2} }distances = torch.sqrt(torch.sum((train_point - test_point)**2, dim=1)) -
曼哈顿距离
Distances = \left | x_{1}-x_{2} \right | + \left | y_{1}-y_{2} \right |distances = torch.sum(torch.abs(train_point - test_point),dim=1)
构造数据集
上一篇笔记中我们已经学过如何用PyTorch进行随机数据的构建,我们此次可以通过 torch.rand() 方法进行随机点集的生成,然后指定一个线性函数对数据进行分类,当然,我们还可以用Matplotlib处理让数据可视化。
def generate_data(a, b, num_train=4000, num_test=1000):
"""生成线性分类数据集"""
# 生成随机点
x_train = torch.rand(num_train) * 20 - 10 # [-10, 10]
y_train = torch.rand(num_train) * 20 - 10
x_test = torch.rand(num_test) * 20 - 10
y_test = torch.rand(num_test) * 20 - 10
# 确定颜色 (直线上方为红色,标签记为1,下方或正好在线上为蓝色,标签记为0)
# 通过zip(x_train, y_train)方式把合成(x,y)
train_colors = torch.tensor([1 if y > a*x + b else 0 for x, y in zip(x_train, y_train)])
test_colors = torch.tensor([1 if y > a*x + b else 0 for x, y in zip(x_test, y_test)])
# 组合训练集和测试集
train_data = torch.stack([x_train, y_train], dim=1)
test_data = torch.stack([x_test, y_test], dim=1)
return train_data, train_colors, test_data, test_colors
定义了一个生成训练集和测试集的方法,其实在KNN中,我们并没有显式的训练过程,而是直接依赖于我们的样本空间,不过鉴于习惯,还是将样本空间命名为数据集。
train_data, train_labels, test_data, test_labels = generate_data(a, b)
接下来我们调用这个方法,传入我们斜率和截距,进行数据的生成。
#上文调用函数的a和b分别是斜率和截距
a = 1.14 # 斜率
b = -2.713 # 截距
绘制图像
在初学分类算法、回归算法时,数据的可视化可以极大程度上助于我们更好的学习和理解这些算法,那么我们自然要使用强大的 Matplotlib 进行图像绘制**。**
def plot_data(a, b, data, labels, show_line=True):
#设置图表宽和高
plt.figure(figsize=(10, 8))
# 绘制数据点
#布尔索引操作:选择所有标签为1(即直线上方)的点(通过索引对应选取)
red_points = data[labels == 1]
blue_points = data[labels == 0]
# red_points[:, 0] 取所有行的第一列,即所有红色点的x坐标,结果是一个一维数组
plt.scatter(red_points[:, 0], red_points[:, 1], color='red', alpha=0.55, label='Above Line')
plt.scatter(blue_points[:, 0], blue_points[:, 1], color='blue', alpha=0.55, label='Below Line')
# 绘制答案直线
if show_line:
#通过torch.linspace在区间[-10,10]直接平分出100个x点,带入计算得到plot所需的x,y点集
#因为我们生成的训练集就是[-10,10]范围的,所以我们的图当然也在这个范围
x_line = torch.linspace(-10, 10, 100)
y_line = a * x_line + b
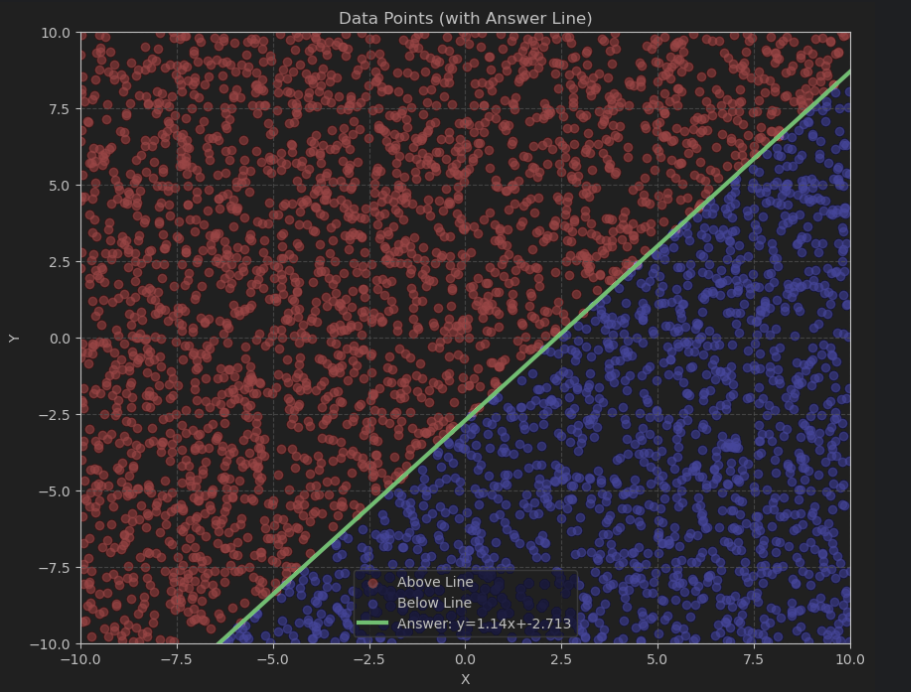
plt.plot(x_line, y_line, 'g-', linewidth=3, label=f'Answer: y={a}x+{b}')
plt.title(f"Data Points ({'with' if show_line else 'without'} Answer Line)")
plt.xlabel('X')
plt.ylabel('Y')
plt.xlim(-10, 10)
plt.ylim(-10, 10)
plt.grid(True, linestyle='--', alpha=0.7)
plt.legend()
plt.show()
接下来我们调用这个方法,进行图像的绘制。注意到我在定义这个方法时设置了一个参数 show_line ,这个参数可以决定我们绘制图像的时候是否绘制分割线。
plot_data(a, b, train_data, train_labels, show_line=False)
plot_data(a, b, train_data, train_labels, show_line=True)
KNN分类机的创建
到这里就是我们的重头戏了,创建一个KNN分类器。
这里我用到了python的面向对象,这有助于我们创建出一个标准化的易于维护和改造的KNN分类器。
class KNNClassifier:
def __init__(self, k=5):
self.k = k
self.X_train = None
self.Y_train = None
def fit(self, X, Y):
"""存储训练数据"""
self.X_train = X #点的坐标张量
self.Y_train = Y #点的标签(0或1)张量
def predict(self, X):
"""预测输入数据的类别"""
predictions = []
# 转换为张量以确保兼容性
if not torch.is_tensor(X):
X = torch.tensor(X, dtype=torch.float32)
# 批量计算距离以提高效率
for test_point in X:
# 计算欧氏距离
#distances = torch.sqrt(torch.sum((self.X_train - test_point)**2, dim=1))
# 计算曼哈顿距离
distances = torch.sum(torch.abs(self.X_train - test_point),dim=1)
'''KNN算法的核心步骤 找到最近的k个邻居'''
# 获取最近的k个样本(largest=False: 表示选择最小而非最大的值)
# 第一个返回值: 最小的k个距离值(用_忽略)
_, indexes = torch.topk(distances, self.k, largest=False)
k_nearest_labels = self.Y_train[indexes]
# 统计整数张量中每个值出现的次数,投票决定类别
counts = torch.bincount(k_nearest_labels)
# 用torch.argmax返回张量中最大值所在的索引,item()将单元素张量转换为Python标量
predictions.append(torch.argmax(counts).item())
return torch.tensor(predictions)
这里我们用到了PyTorch提供的非常好用的方法
_, indexes = torch.topk(distances, self.k, largest=False)
counts = torch.bincount(k_nearest_labels)
predictions.append(torch.argmax(counts).item())
注意到这三行出现了三个新面孔,分别是torch.topk(),torch.bincount()和torch.argmax()
我们可以通过IDE自带的查询功能来阅读这三个方法的作用。
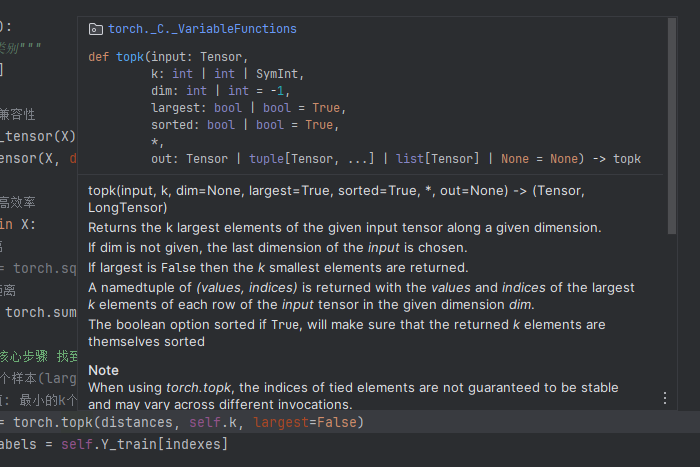
比如 torch.topk() 就可以在传入的张量中挑选出最大或者最小个k个,然后把数据和索引返回给我们。
torch.bincount() 函数用于统计离散值的出现次数,而 torch.argmax() 可以把最大值的索引返回给我们.
在我们构建好KNN模型后,就可以开始使用并且评估了
def train_and_evaluate(K, train_data, train_labels, test_data, test_labels):
"""训练KNN模型并评估性能"""
# 创建并训练KNN分类器
knn = KNNClassifier(k=K)
knn.fit(train_data, train_labels)
# 预测测试集
start_time = time.time()
test_preds = knn.predict(test_data)
inference_time = time.time() - start_time
# 计算准确率
if test_labels.device != test_preds.device:
test_preds = test_preds.to(test_labels.device)
accuracy = (test_labels == test_preds).float().mean().item()
print(f"K={K} | 测试准确率: {accuracy:.4f} | 推理时间: {inference_time:.4f}秒")
return knn, test_preds, accuracy
k_values = [1,2,3,4,5,7,10,13,15, 20,25]
results = {}
for k in k_values:
knn, test_preds, accuracy = train_and_evaluate(k, train_data, train_labels, test_data, test_labels)
results[k] = {
'model': knn,
'predictions': test_preds,
'accuracy': accuracy
}
根据输出结果来看
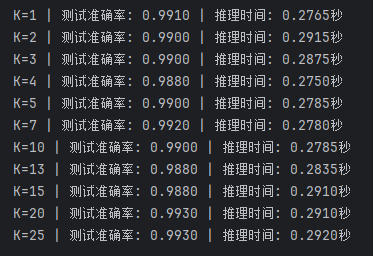
其实不太好看
那么怎么办?
当然还是使用 Matplotlib 了!
plt.figure(figsize=(10, 6))
accuracies = [results[k]['accuracy'] for k in k_values]
plt.plot(k_values, accuracies, 'bo-', linewidth=2, markersize=8)
plt.title('KNN')
plt.xlabel('K')
plt.ylabel('Accuracy')
plt.grid(True, linestyle='--', alpha=0.7)
plt.xticks(k_values)
plt.show()
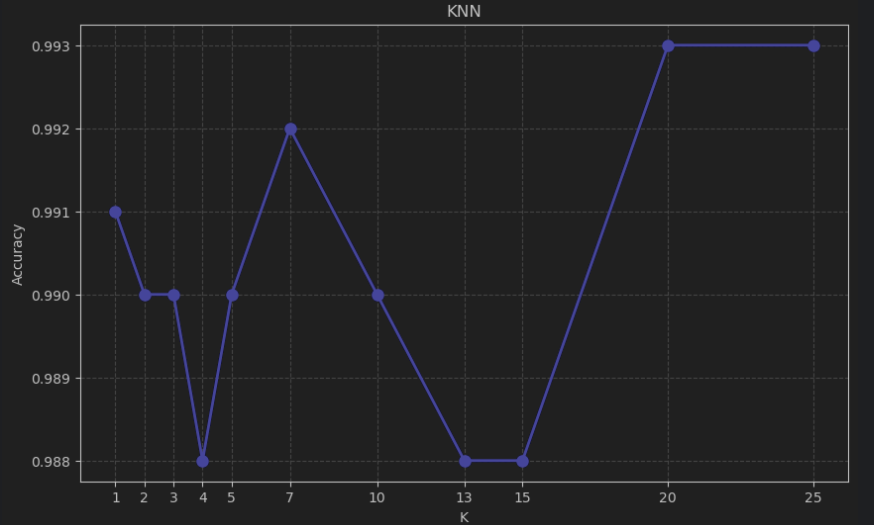
所以我们可以得到在K=7时候有较好结果,而K>20的时候又会出现更好的结果,但是这并不意味着K越大越好!在考虑到计算量大小,数据集大小等因素的情况下,我们可以说这里K=7就是理想情况了,而且对于别的数据分类或回归时,可能并不会出现多个峰值。
决策边界
def plot_decision_boundary(a, b, knn, data, labels):
"""可视化决策边界"""
plt.figure(figsize=(12, 10))
# 绘制数据点
red_points = data[labels == 1]
blue_points = data[labels == 0]
plt.scatter(red_points[:, 0], red_points[:, 1], color='red', alpha=0.5, label='Above Line')
plt.scatter(blue_points[:, 0], blue_points[:, 1], color='blue', alpha=0.5, label='Below Line')
# 绘制答案直线
x_line = torch.linspace(-10, 10, 100)
y_line = a * x_line + b
plt.plot(x_line, y_line, 'g-', linewidth=3, label=f'Answer: y={a}x+{b}')
# 绘制KNN决策边界
resolution = 100
xx, yy = torch.meshgrid(torch.linspace(-10, 10, resolution),
torch.linspace(-10, 10, resolution))
grid_points = torch.stack((xx.flatten(), yy.flatten()), dim=1)
# 预测网格点的类别
start_time = time.time()
grid_preds = knn.predict(grid_points)
print(f"决策边界计算时间: {time.time() - start_time:.2f}秒")
# 创建决策边界图
grid_preds = grid_preds.reshape(xx.shape)
plt.contourf(xx, yy, grid_preds, alpha=0.2, levels=[-0.5, 0.5, 1.5],
colors=['blue', 'red'])
# 绘制KNN近似的决策边界
boundary_line = []
for x in torch.linspace(-10, 10, 50):
# 创建垂直线上的点
y_values = torch.linspace(-10, 10, 100)
test_points = torch.stack([torch.full_like(y_values, x), y_values], dim=1)
# 预测这些点的类别
preds = knn.predict(test_points)
# 找到决策边界的位置
diff = torch.abs(torch.diff(preds.float()))
if torch.any(diff > 0):
idx = torch.argmax(diff).item()
y_boundary = (y_values[idx] + y_values[idx+1]) / 2
boundary_line.append([x.item(), y_boundary.item()])
if boundary_line:
boundary_line = np.array(boundary_line)
plt.plot(boundary_line[:, 0], boundary_line[:, 1], 'm--', linewidth=3,
label=f'KNN Boundary (k={knn.k})')
plt.title(f"KNN Decision Boundary (k={knn.k})")
plt.xlabel('X')
plt.ylabel('Y')
plt.xlim(-10, 10)
plt.ylim(-10, 10)
plt.grid(True, linestyle='--', alpha=0.3)
plt.legend()
plt.show()
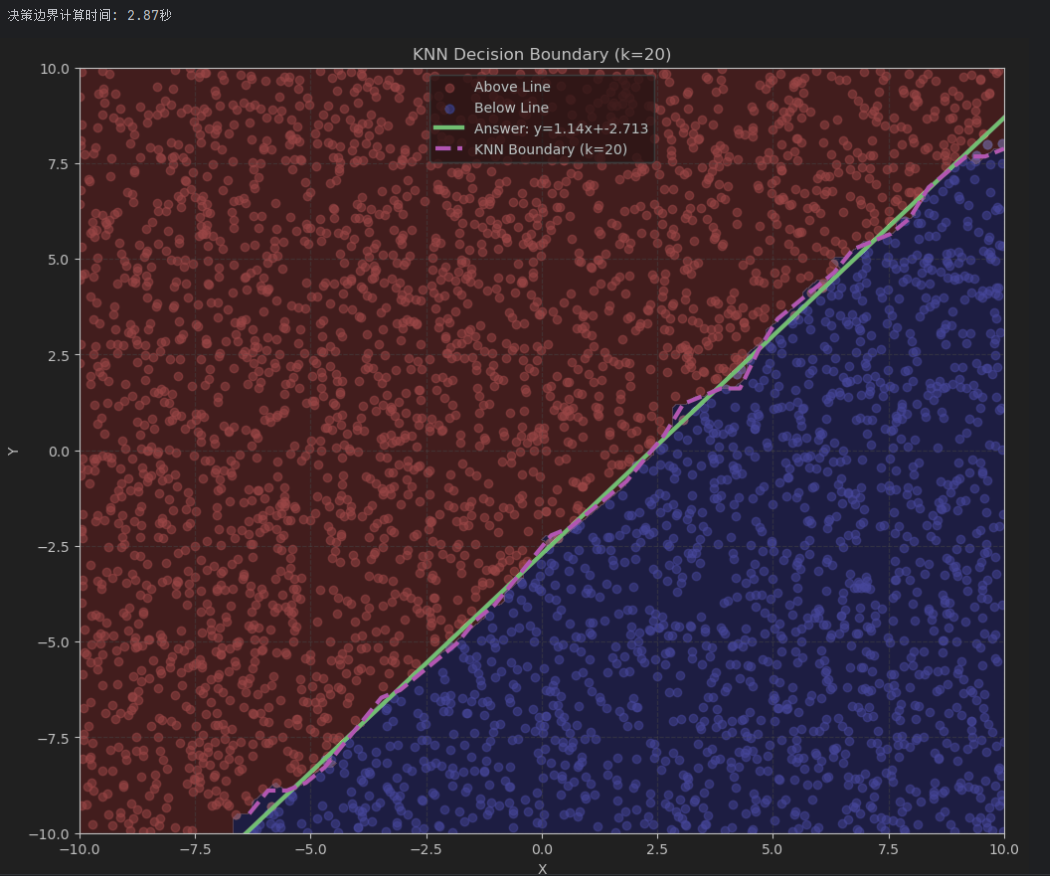
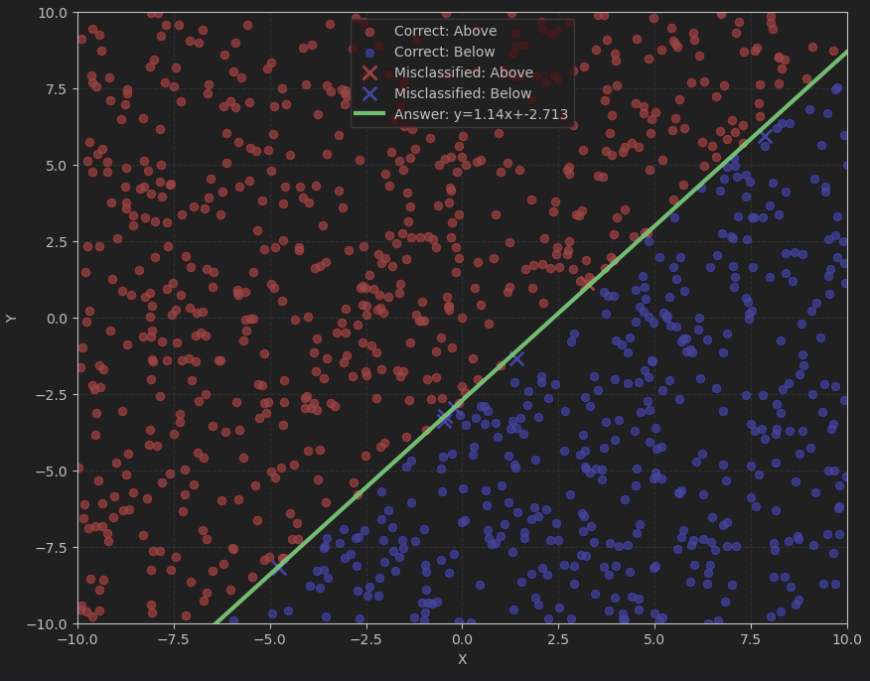
测试集结果可视化
# 可视化测试集结果
plt.figure(figsize=(10, 8))
# 绘制测试点,使用不同形状表示预测是否正确
correct_indices = (test_preds == test_labels)
incorrect_indices = ~correct_indices
# 正确分类的点
correct_points = test_data[correct_indices]
correct_labels = test_labels[correct_indices]
correct_red = correct_points[correct_labels == 1]
correct_blue = correct_points[correct_labels == 0]
# 错误分类的点
incorrect_points = test_data[incorrect_indices]
incorrect_labels = test_labels[incorrect_indices]
incorrect_red = incorrect_points[incorrect_labels == 1] # 实际是红色但被错分
incorrect_blue = incorrect_points[incorrect_labels == 0] # 实际是蓝色但被错分
# 绘制正确分类的点
plt.scatter(correct_red[:, 0], correct_red[:, 1], color='red', marker='o', alpha=0.7, label='Correct: Above')
plt.scatter(correct_blue[:, 0], correct_blue[:, 1], color='blue', marker='o', alpha=0.7, label='Correct: Below')
# 绘制错误分类的点
plt.scatter(incorrect_red[:, 0], incorrect_red[:, 1], color='red', marker='x', s=100, linewidth=2, label='Misclassified: Above')
plt.scatter(incorrect_blue[:, 0], incorrect_blue[:, 1], color='blue', marker='x', s=100, linewidth=2, label='Misclassified: Below')
# 绘制答案直线
x_line = torch.linspace(-10, 10, 100)
y_line = a * x_line + b
plt.plot(x_line, y_line, 'g-', linewidth=3, label=f'Answer: y={a}x+{b}')
plt.xlabel('X')
plt.ylabel('Y')
plt.xlim(-10, 10)
plt.ylim(-10, 10)
plt.grid(True, linestyle='--', alpha=0.3)
plt.legend()
plt.show()